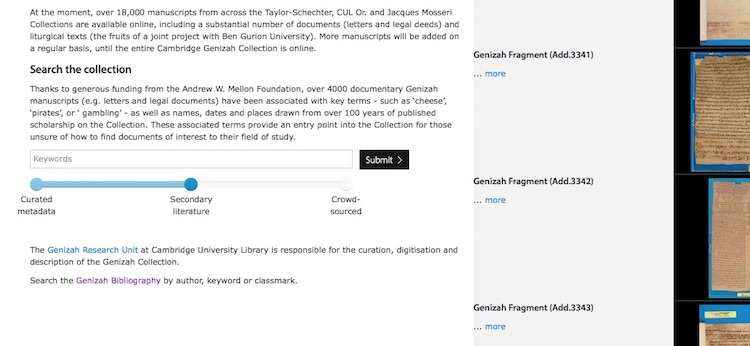
‘Discovering history in the Cairo Genizah’ (2012–16)
http://cudl.lib.cam.ac.uk/collections/genizah
This was a major project funded by the Andrew W. Mellon Foundation, and run by Cambridge University Library’s Genizah Research Unit in cooperation with the Digital Content Unit and Digital Services departments of the Library. It was designed to facilitate discovery of the medieval manuscripts of the Taylor-Schechter Cairo Genizah Collection by using techniques from the fields of text mining, information retrieval and natural language processing to automate the process of producing descriptive catalogue data.
There are more than 100 years of published scholarship on Cambridge’s Genizah Collection – an immense collection of medieval Jewish manuscripts recovered from an Egyptian synagogue. By OCRing as many of those sources as possible, automating the process of extracting keyword data from them and associating those tags with the images of digitised manuscripts, the project has greatly increased the amount of descriptive metadata for more than five thousand of the most important historical documents from the Genizah. These documents relate principally to the history of the Jews under Islam in the tenth to mid-thirteenth centuries CE, for which the Genizah is an unparalleled source. The keyword metadata provides a new way of searching and browsing the Collection across broad subject areas or around distinctive items of vocabulary or key concepts. Furthermore, the interface is able to suggest similar items that might be of interest to the user, based on the similarity of the accrued data.
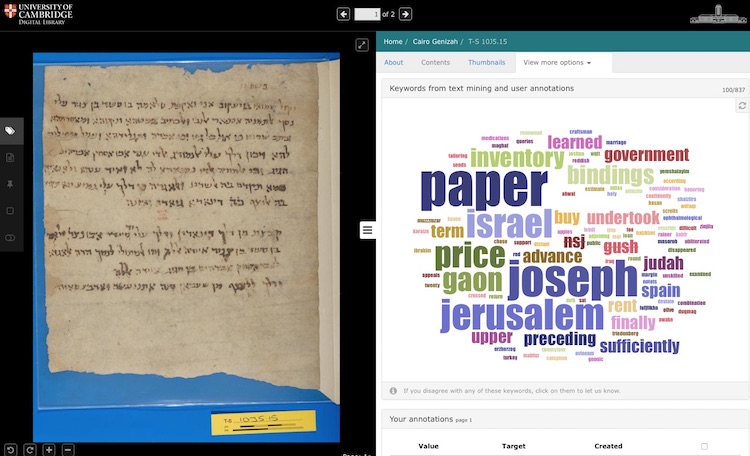
Since the descriptive tags have been derived automatically, new features have been added to the interface to allow users to reject those tags or add their own in various ways. This feedback is collected, weighted according to an authority model, and incorporated into the metadata, allowing the search and browse data to be refined over time and use.
An article describing the text-mining techniques employed can be read in Manuscript Cultures 7, pp. 29–34, available online here:
http://www.manuscript-cultures.uni-hamburg.de/MC/manuscript_cultures_no_7.pdf