‘Discovering history in the Cairo Genizah’ (2012–16)
This was a major project funded by the Andrew W. Mellon Foundation, and run by Cambridge University Library’s Genizah Research Unit in cooperation with the Digital Content Unit and Digital Services departments of the Library. It was designed to facilitate discovery of the medieval manuscripts of the Taylor-Schechter Cairo Genizah Collection by using techniques from the fields of text mining, information retrieval and natural language processing to automate the process of producing descriptive catalogue data.
There are more than 100 years of published scholarship on Cambridge’s Genizah Collection – an immense collection of medieval Jewish manuscripts recovered from an Egyptian synagogue. By OCRing as many of those sources as possible, automating the process of extracting keyword data from them and associating those tags with the images of digitised manuscripts, the project has greatly increased the amount of descriptive metadata for more than five thousand of the most important historical documents from the Genizah. These documents relate principally to the history of the Jews under Islam in the tenth to mid-thirteenth centuries CE, for which the Genizah is an unparalleled source. The keyword metadata provides a new way of searching and browsing the Collection across broad subject areas or around distinctive items of vocabulary or key concepts. Furthermore, the interface is able to suggest similar items that might be of interest to the user, based on the similarity of the accrued data.
Since the descriptive tags are derived automatically, features have been added to the interface to allow users to reject those tags or add their own in various ways. This feedback is collected, weighted according to an authority model, and incorporated into the metadata, allowing the search and browse data to be refined over time and use.
To search the tagged data, use the search found here:
http://cudl.lib.cam.ac.uk/collections/genizah
A login is required (various login options are given).

The search slider can be used to narrow or broaden the metadata source. ‘Curated metadata’ searches within catalogue entries written by Genizah Research Unit staff. If the search is widened to ‘Secondary literature’ the search will include tags generated by the text mining of 100 years of published scholarship on the Genizah fragments. ‘Crowd-sourced’ metadata includes all tags added by users. On the item page for a Genizah fragment there is a tab 'View more options', through which you can download an image or the metadata of the fragment, view items deemed to be similar, and view tags associated with the fragment. Text-mined data tags are given as a word-cloud visualisation, in which the relative size of the keyword indicates its relevance. Clicking on an individual term in the word-cloud allows you to mark the terms as irrelevant to the document, and it will decrease in importance in subsequent searches. If enough users mark a term as irrelevant, it will cease to be associated with that fragment altogether. Refreshing the tag cloud causes a different set of its keywords to be displayed.
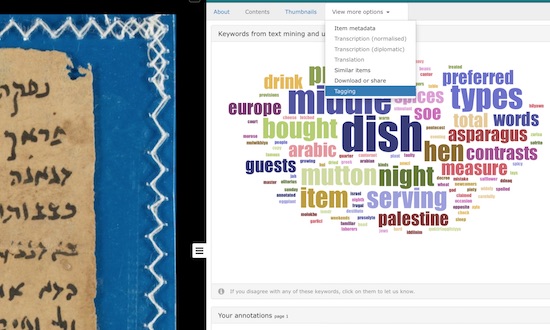
A user can also add their own annotations, tagging the page as a whole, or a point or region on the document. Four different types of annotation can be added via the relevant options displayed at the left side of the page: names of individuals who feature in the document, what it’s about, its date, and place names. The annotations can be toggled on or off. All user annotations are indexed nightly, which means that they will become publicly searchable within a very short space of time.
Publications
An article describing the text-mining techniques employed can be read in Manuscript Cultures 7, pp. 29–34, available here:
http://www.manuscript-cultures.uni-hamburg.de/MC/manuscript_cultures_no_7.pdf
More general information on the project can be found in two issues of our newsletter, Genizah Fragments:
http://www.lib.cam.ac.uk/Taylor-Schechter/GF/Genizah_Fragments_66.pdf
http://www.lib.cam.ac.uk/files/genizah_72.pdf
The project software
The project team have released the software that was specifically created to run the project under an open licence (https://opensource.org/licenses/BSD-2-Clause). Project software can be downloaded from the project's BitBucket site:
https://bitbucket.org/account/user/CUDL/projects/CT
The first part of the project was the collection of catalogue data, keywords that described specific manuscripts, which were derived by running text retrieval on a corpus of machine-readable (UTF-8) text. The Text-Mining Script was created in Perl for the project and can be obtained from the code repository:
https://bitbucket.org/CUDL/genizah-discovery
This is a program that uses text mining techniques to discover terms that are associated with Genizah manuscripts. Terms are weighted with a value indicating their importance(/significance). This is achieved by identifying sections of published literature that refer to specific fragments. References to fragments are established based on occurances of a fragment's classmark (which usually begins 'T-S ...') in the literature. Terms are extracted from these associated literature sections, and weighted by considering the significance of the terms in the context of the literature corpus as a whole. There is also a web-based tool to allow the text-mined data to be searched and visualised.
These text-mined keywords were added as annotations to manuscripts mounted on Cambridge Digital Library. Using the CUDL Tagging Service, crowdsourced annotations can be added to the annotation database and tags can be corrected by users. Specifically, the Tagging Service allows:
- the creation of annotations against document pages and their retrieval
- the fetching of weighted terms associated with a document
- the export of contributions in bulk as RDF XML
- the marking of weighted terms as inaccurate
The weighted terms are strengthened by annotations created by users and weakened by inaccuracy marks added by users.
The codebase is generic in nature and can be reused outside the CUDL viewer. The only CUDL-specific piece of the web service is the image resolver, which uses CUDL's internal JSON metadata format, and a different implementation could be used without radically changing the codebase.
The CUDL Tagging Service can be obtained here:
https://bitbucket.org/CUDL/cudl-tagging-service/
and the Tagging Service's HTTP API is documented here:
https://bitbucket.org/CUDL/cudl-tagging-service/src/master/docs/api.md
The CUDL Viewer Tagging UI implements the functionality seen in CUDL when the 'Tagging' tab is selected when viewing a Genizah fragment. This functionality comprises:
- an overlay to the CUDL zooming image, providing the ability to (a) view point- and region-based annotations on the image; (b) add, edit and delete annotations at the page, point and rectangular-region level
- a sidebar containing
(a) a word cloud that (i) visualises the weighted terms associated with the item via the size of words in the cloud and (ii) allows the reporting of inaccurate terms by the user clicking on words in the cloud to strike them out
(b) a list of annotations, including page-level annotations that are not represented on the image itself
- buttons to export annotation contributions as RDF XML
The CUDL Viewer Tagging UI can be obtained here:
https://bitbucket.org/CUDL/cudl-viewer-tagging-ui
This functionality is backed by the corresponding functionality provided by the CUDL Tagging Service. The UI was designed to work closely with the CUDL UI, and therefore it may be more useful as a example of how the Tagging Service can be used to implement a similar workable UI.
Have a question or need further information? Please send inquiries to: digitalhumanities@lib.cam.ac.uk